本文内容包括:
- 一、入门翻唱:免费用自己声音翻唱一首歌;
- 二、专业翻唱:训练更多优质模型和翻唱更多歌曲;
- 三、企业接入:快速拥有翻唱歌曲的能力;
一、入门翻唱
今天翻唱的平台是“绘声美音”公众号,对用户比较友好:
- 首先,简单,只需要一部手机,不用电脑显卡,不需要下载软件,不需要魔法;
- 然后,自助式,不需要人工干预,更高效,点歌台提供80万首歌和10万支MV;
- 最后,新用户免费,可以训练声音模型和翻唱一首歌。
入门阶段的目标是用自己声音翻唱一首歌:
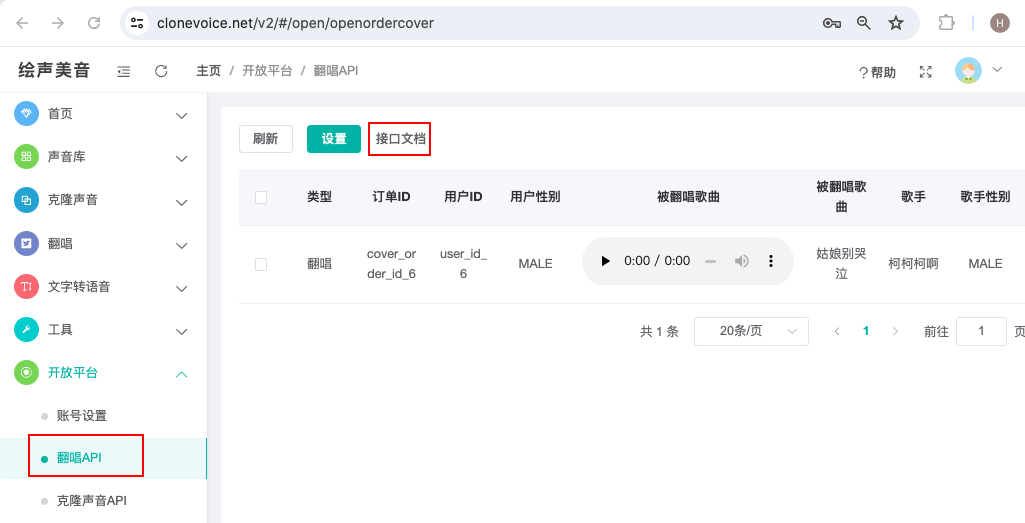
首先进入“绘声美音”公众号,找到“AI翻唱”菜单,这里标记了1、2、3,这也是翻唱歌曲的步骤。
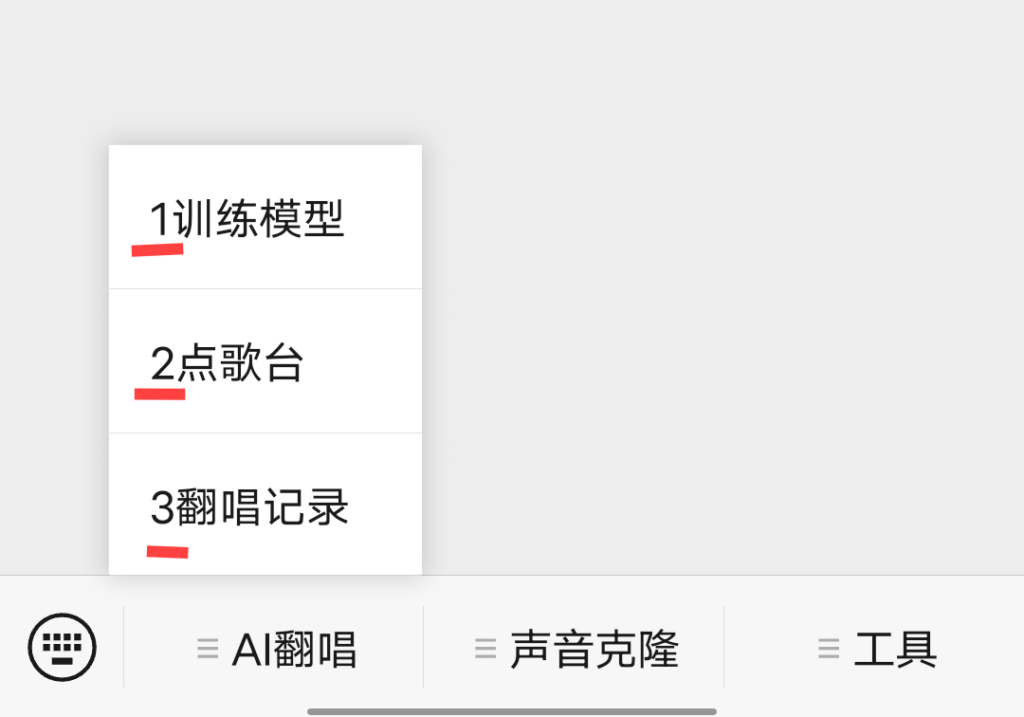
第1步、训练声音模型,根据提示,首先选择性别,然后上传样本,也就是朗读文章。为了保证样本质量,尽量在安静的环境下,大声朗读3分钟。然后就点击“开始训练声音模型”。训练模型时间大约15分钟。步骤如下图:
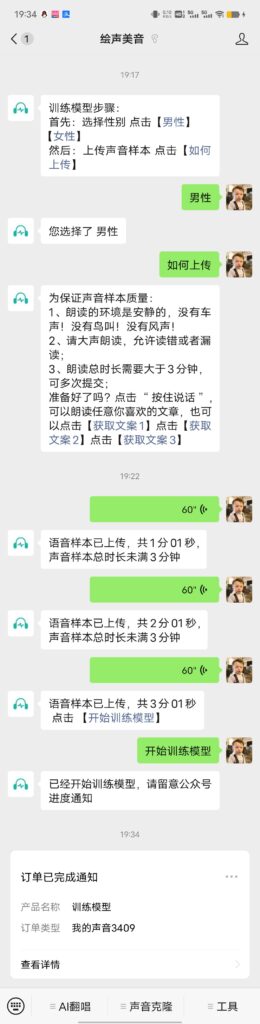
第2步、打开“点歌台”菜单,一键翻唱,大约5分钟出结果,请关注公众号通知。
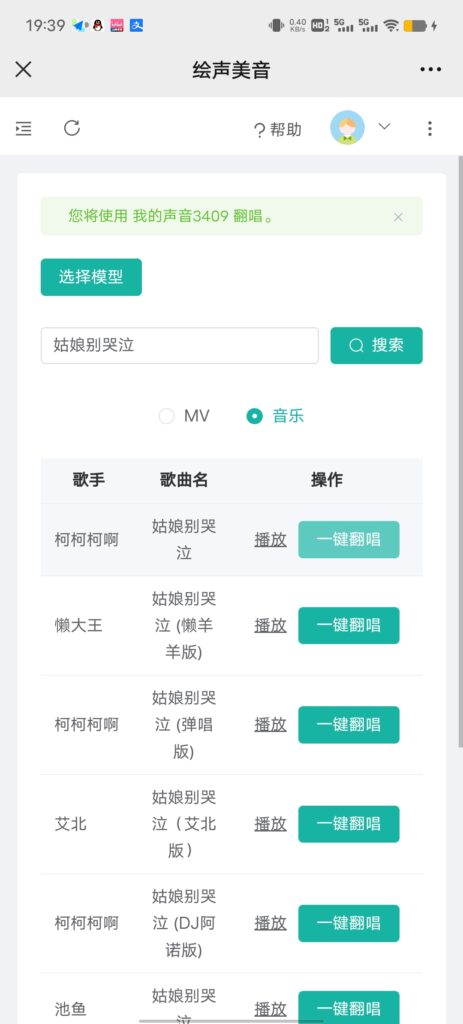
第3步,点击“翻唱记录”菜单,查看翻唱结果。
二、专业翻唱
专业翻唱的目标是训练更多优质模型和翻唱更多歌曲。
在“点歌台“菜单和”翻唱记录“菜单都有“RVC声音库”的按钮,打开RVC声音库,能看到有两个按钮,“上传模型”和“训练模型”。
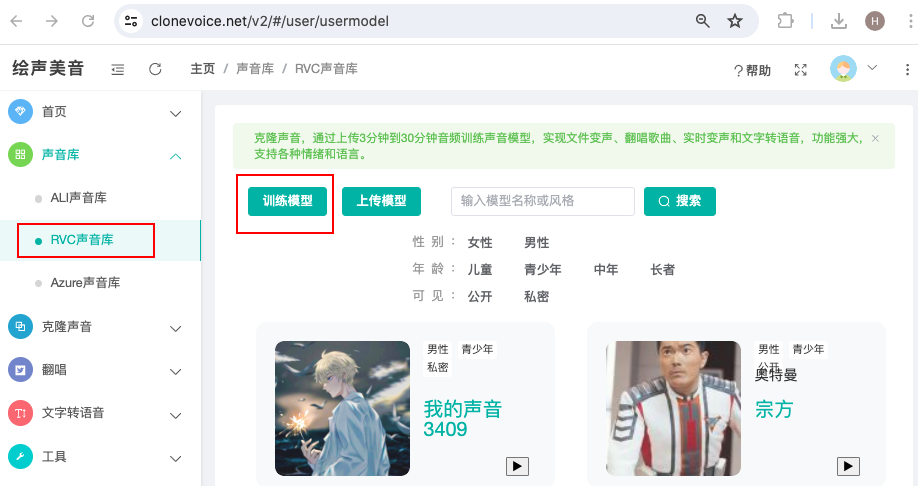
上传模型:训练好的RVC模型包括.pth和.index两种格式的文件,这里只需上传.pth格式文件。
训练模型:训练模型(即炼丹),是提取声音特征,将音色保存到模型文件的过程。
2.1 训练模型步骤
点击“RVC声音库”菜单,再点击右边的“训练模型”,打开下界面:

- 第1步:输入模型名称,用于标记模型,比如你自己的姓名;
- 第2步:选择性别,即这个声音模型的性别,在实现跨性别翻唱时很有用;
- 第3步:如果选择公开,那么所有人都能看到和使用这个声音模型;
- 第4步:总轮数,选择300轮差不多,最多可以选择1000epoch;
- 第5步:上传训练素材;
2.2 训练素材要求
翻唱歌曲的原理是替换歌曲中的音色,所以声音样本很重要。:
- 1、如果不能确定素材质量,最好的办法是先在“UVR5提取干声”菜单提取干声,确保这个干声只出现一个人的声音,没有杂音,不符合要求的素材丢掉,原则是宁缺毋滥。
- 2、符合要求的声音素材,大约3~30分钟,越多翻唱后歌曲越丝滑。
- 3、如果翻唱前的歌曲有高音,那么素材里也要有高音。翻唱后发现有高音部分是哑音,那么可能是缺少高音样本。
实操案例:手把手教你训练“那兔”声音模型 https://www.clonevoice.net/article/?p=1944
三、企业接入
接入翻唱API是拥有翻唱能力最快的方式。上传一段的音频、一首歌及相关参数,可以得到翻唱后的歌曲。
这个过程,可能需要使用音乐库API。
甲方需要提供回调接口,用于接收翻唱后的歌曲。