.png)
声音模型是实现变声翻唱等声音转换的前提。在克隆声音网站里,用户获得声音模型方式:
第一种:RVC模型社区,也就是声音库,这里有许多用户公开免费的高质量RVC声音模型,其中一些是明星的声音模型;
第二种:上传声音模型,如果你有RVC声音模型,里面有一个.pth格式的模型文件,可以在模型社区上传;登录后,点击左边的“声音库”菜单,有“上传模型”按钮。
第三种:电脑训练RVC声音模型,不仅可以训练自己的声音模型,还可以训练他人的声音模型;登录后,点击左边的“声音库”菜单,有“训练模型”按钮。
第四种:手机训练RVC声音模型,适合训练自己的声音模型。根据“绘声美音”公众号的下方菜单“克隆声音”提示可以完成。
手机制作声音模型步骤
请阅读完本文后,再操作。
本文基于RVC项目训练声音模型。
一、关注“绘声美音”公众号
会收到如下提示

二、点击上图“上传须知” 准备环境
如下图:

1、朗读的环境是安静的,没有车声!没有鸟叫!没有风声!
2、请大声朗读,允许读错或者少读;
3、朗读总时长需要大于3分钟,可多次提交;
三、大声朗读,上传语音样本
大声朗读的内容可以是上面的文案1、文案2、文案3,也可以是你喜欢的文案。在绘声美音“”公众号“按住说话”,上传你的语音样本。
总时长要大于3分钟。

四、开始训练语音模型
普通用户可以免费训练一个模型,使用200EPOCH。VIP用户则可以使用300epoch训练模型,也就是300轮次。电脑登录后,训练模型甚至可以到1000epoch。
当上传语音满3分钟后,出现下面提示。点击“结束录音,开始训练”
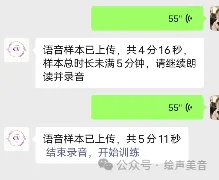
五、训练模型结束,收到提醒
大约30分钟,您的声音模型训练完成。公众号会收到消息,如下图。这时声音模型已经训练成功。
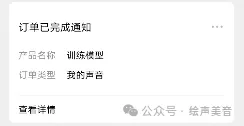
结束:
声音模型下载办法:电脑登录https://www.clonevoice.net/v2/ 后,在声音库里找到模型,点击进入详情,点击修改,可以看到“下载”按钮。
到现在为止,你用到硬件的只有手机,你并不需要任何显卡,不需要提取干音,也不需要使用UVR5,更加不用下载几个G的文件和配置环境变量,因为我们把这些困难点都封装到云端,给大家提供便捷的克隆声音服务。


Pingback: AI翻唱歌曲 有手机就行 – 克隆声音,AI变声,实时变声服务,视频变声,免费的文本转语音服务